この論文では、非常に高速に画像を処理しながら高い検出率を達成できる視覚物体検出フレームワークについて説明する。3 つの重要な貢献がある。1 つ目は、「積分画像」と呼ばれる新しい画像表現の導入である。これにより、検出器で使用される特徴を非常に高速に計算できる。2 つ目は、AdaBoost に基づく学習アルゴリズムである。これは、少数の重要な視覚的特徴を選択し、非常に効率的な分類器を生成する[6]。3 つ目は、分類器を「カスケード(縦続接続)」で組み合わせる方法である。これにより、画像の背景領域をすばやく棄却し、有望な物体のような領域に多くの計算を費やすことができる。顔検出の領域での一連の実験を提示する。このシステムは、これまでの最高のシステムに匹敵する顔検出パフォーマンスを実現する [18、13、16、12、1]。一般的なデスクトップに実装すると、顔検出は 1 秒あたり 15 フレームで進行する。
この論文では、新しいアルゴリズムと洞察を統合して、堅牢で極めて高速な物体検出のフレームワークを構築する。このフレームワークは、動機の一部である顔検出のタスクで実証されている。この目的のために、我々は、公開されている最高の結果 [18、13、16、12、1] と同等の検出率と誤検出率を実現する正面顔検出システムを構築した。この顔検出システムは、顔を極めて高速に検出する能力において、これまでのアプローチと最も明確に区別される。384 x 288 ピクセルの画像で動作し、一般的な 700 MHz Intel Pentium III で 1 秒あたり 15 フレームで顔が検出される。他の顔検出システムでは、ビデオ シーケンスの画像の違いやカラー画像のピクセルの色などの補助情報を使用して、高フレーム レートを実現している。我々のシステムは、単一のグレースケール画像に存在する情報のみを使用して高フレーム レートを実現する。これらの代替情報源を我々のシステムに統合して、さらに高いフレーム レートを実現することもできる。
我々の物体検出フレームワークには、3 つの主な貢献がある。以下では、これらのアイデアをそれぞれ簡単に紹介し、その後のセクションで詳しく説明する。
この論文の最初の貢献は、非常に高速な特徴評価を可能にする積分画像と呼ばれる新しい画像表現である。Papageorgiou らの研究に一部基づいて、我々の検出システムは画像強度を直接処理しない [10]。これらの著者と同様に、我々は Haar 基底関数を彷彿とさせる一連の特徴を使用する (ただし、Haar フィルターよりも複雑な関連フィルターも使用する)。これらの特徴をさまざまなスケールで非常に高速に計算するために、画像の積分画像表現を導入する (積分画像は、テクスチャ マッピング用のコンピューター グラフィックスで使用される合計エリアテーブル [3] に非常に似ている)。積分画像は、ピクセルごとにいくつかの操作を使用して画像から計算できる。一度計算すると、これらの Harr-like特徴の 1 つを任意のスケールまたは場所で一定時間で計算できる。
本論文の 2 つ目の貢献は、AdaBoost [6] を使用して少数の重要な特徴を選択して分類器を構築する方法である。画像のサブウィンドウ内では、Harr-like特徴の総数は非常に多く、ピクセルの数よりもはるかに多くなる。高速な分類を確実に行うには、学習プロセスで利用可能な特徴の大部分を除外し、重要な特徴の小さなセットに焦点を当てる必要がある。Tieu と Viola の研究に触発されて、特徴選択は AdaBoost 手順の単純な変更によって実現される。つまり、弱学習器は、返される各弱分類器が 1 つの特徴のみに依存できるように制約される [2]。その結果、新しい弱分類器を選択するブースティング プロセスの各段階は、特徴選択プロセスと見なすことができる。AdaBoost は、効果的な学習アルゴリズムと、一般化パフォーマンスの強力な境界を提供する [14、9、10]。
この論文の 3 つ目の大きな貢献は、画像の有望な領域に注意を集中させることで検出器の速度を大幅に向上させる、カスケード構造で連続的に複雑な分類器を組み合わせる方法である。注意の焦点アプローチの背後にある概念は、画像内のどこにオブジェクトが発生する可能性があるかを迅速に判断できることが多いということである [19、8、1]。より複雑な処理は、これらの有望な領域に対してのみ行われる。このようなアプローチの重要な指標は、注意プロセスの「偽陰性」率である。すべての、またはほぼすべてのオブジェクトインスタンスが注意フィルターによって選択される必要がある。
ここでは、教師ありの注目度オペレータとして使用できる、非常にシンプルで効率的な分類器をトレーニングするプロセスについて説明する。教師ありという用語は、注目度オペレータが特定のクラスの例を検出するようにトレーニングされることを意味する。顔検出の分野では、20 回の簡単な操作 (約 60 個のマイクロプロセッサ命令) で評価できる分類器を使用して、1% 未満の偽陰性と 40% の偽陽性を達成できる。このフィルタの効果は、最終的な検出器を評価する必要がある場所の数を半分以上削減することである。
最初の分類器によって棄却されなかったサブウィンドウは、それぞれが前のものよりわずかに複雑な一連の分類器によって処理される。いずれかの分類器がサブウィンドウを棄却した場合、それ以上の処理は実行されない。カスケード検出プロセスの構造は、本質的には退化した決定木の構造であり、Amit と Geman [1] の研究に関連している。
完全な顔検出カスケードには 32 の分類器があり、合計で 80,000 回以上の操作が行われる。それでも、カスケード構造により、平均検出時間は非常に短くなる。507 の顔と 7,500 万のサブウィンドウを含む難しいデータセットでは、サブウィンドウあたり平均 270 のマイクロプロセッサ命令を使用して顔が検出される。比較すると、このシステムは、Rowley らが構築した検出システムの実装よりも約 15 倍高速である。1 [13]
1 Henry Rowley 氏は、直接比較できるように、彼の検出システムの実装を非常に親切に提供してくれた。報告された結果は、彼の最速システムと比較したものである。公開された文献から判断するのは困難であるが、Rowley-Baluja-Kanade 検出器は、最も高速な検出システムとして広く考えられており、実際の問題で徹底的にテストされている。
非常に高速な顔検出器は、幅広い実用的な用途に使用できる。これには、ユーザー インターフェイス、画像データベース、およびテレビ会議が含まれる。この速度の向上により、以前は実現不可能だったシステムでリアルタイムの顔検出アプリケーションが可能になる。高速フレーム レートが不要なアプリケーションでは、我々のシステムにより、大幅な追加の後処理と分析が可能になる。さらに、我々のシステムは、ハンドヘルドや組み込みプロセッサなど、さまざまな小型低電力デバイスに実装できる。我々の研究室では、この顔検出器を Compaq iPaq ハンドヘルドに実装し、1 秒あたり 2 フレームの検出を実現した (このデバイスには、浮動小数点ハードウェアのない低電力 200 mips Strong Arm プロセッサが搭載されている)。
論文の残りのセクションでは、検出器の実装、関連理論、および実験について説明する。セクション 2 では、特徴の形式と、それらを迅速に計算するための新しいスキームについて詳しく説明する。セクション 3 では、これらの特徴を組み合わせて分類器を形成する方法について説明する。使用される機械学習方法は、AdaBoost のバリエーションであり、特徴選択メカニズムとしても機能する。この方法で構築された分類器は、計算と分類のパフォーマンスは優れているが、リアルタイム分類器としては遅すぎる。セクション 4 では、非常に信頼性が高く効率的なオブジェクト検出器を生成する分類器のカスケードを構築する方法について説明する。セクション 5 では、実験方法の詳細な説明を含むいくつかの実験結果について説明する。最後に、セクション 6 では、このシステムと関連システムとの関係について説明する。
我々の物体検出手順は、単純な特徴の値に基づいて画像を分類する。ピクセルを直接使用するのではなく、特徴を使用する動機は数多くある。最も一般的な理由は、特徴は、限られた量のトレーニング データを使用して学習するのが難しいアドホックなドメイン知識をエンコードする役割を果たすことができるということである。このシステムでは、特徴を使用するもう 1 つの重要な動機もある。それは、特徴ベースのシステムはピクセルベースのシステムよりもはるかに高速に動作するということである。
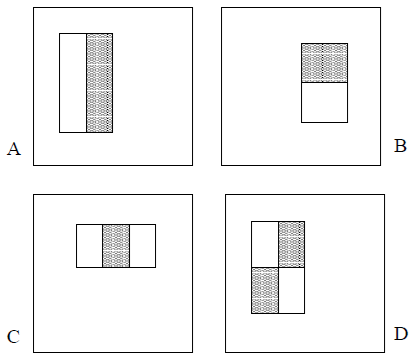
使用される単純な特徴は、Papageorgiou ら [10] が使用した Haar 基底関数を彷彿とさせる。より具体的には、3 種類の特徴を使用する。2 つの長方形の特徴の値は、2 つの長方形領域内のピクセルの合計の差である。領域は同じサイズと形状を持ち、水平または垂直に隣接している (図 1 を参照)。3 つの長方形の特徴は、中央の長方形の合計から外側の 2 つの長方形の合計を減算して計算する。最後に、4 つの長方形の特徴は、対角線の長方形のペア間の差を計算する。
図 1: 検出ウィンドウを基準にして表示される矩形特徴の例。白い矩形内のピクセルの合計から、灰色の矩形内のピクセルの合計が引かれる。2 つの矩形特徴が (A) と (B) に示されている。図 (C) は 3 つの矩形特徴を示し、(D) は 4 つの矩形特徴を示している。
検出器の基本解像度が 24x24 であることを考えると、矩形特徴の網羅的な集合は 45,396 とかなり大きくなる。Haar 基底とは異なり、矩形特徴の集合トは過完備 2 であることに注意。
2 完備な基底では、基底要素間に線形依存関係がなく、画像空間と同じ数の要素 (この場合は24×24= 576) がある。45,396個の特徴の全集合は、何倍も完備すぎる。
矩形特徴は、画像の中間表現(積分画像と呼ぶ)を使用して非常に高速に計算できる。3 位置 \(x,y\) の積分画像には、\(x,y\) の上と左のピクセルの合計が含まれる。 \[ ii(x,y)=\sum_{x'\leq x,y'\leq y} i(x',y') \] ここで、\(ii(x,y)\)は積分画像、\(i(x,y)\)は元の画像である(図2を参照)。
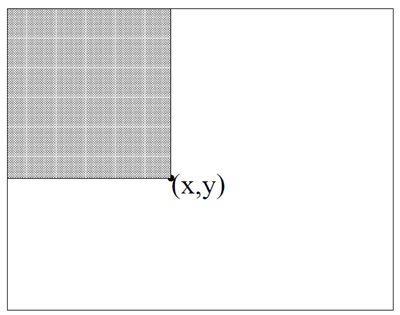
図2: 点\((x,y)\)における積分画像の値は、その上と左にあるすべてのピクセルの合計である。
次の繰り返しのペアを使用する。 \[ \begin{align} s(x,y) &=s(x,y-1)+i(x,y) \tag{1} \\ ii(x,y) &=ii(x-1,y)+s(x,y) \tag{2} \end{align} \] ここで、\(s(x,y)\) は行の累積合計で \(s(x,-1)=0\), および \(ii(x,y)\) は積分画像で \(ii(-1,y)=0\)。元の画像に対して1回のパスで計算できる。
3 これはグラフィックスで使用される「エリア合計テーブル」と密接な関係がある[3]。ここでは、テクスチャマッピングではなく画像解析での使用を強調するために別の名前を選択する。
積分画像を使用すると、任意の矩形の合計を 4 つの配列参照で計算できる(図 3 を参照)。
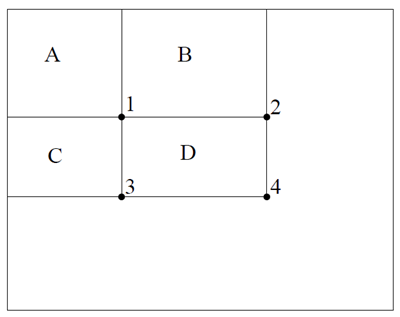
図 3: 矩形 \(D\) 内のピクセルの合計は、4 つの配列参照を使用して計算できる。位置 1 の積分画像の値は、矩形 \(A\) 内のピクセルの合計である。位置 2 の値は \(A+B\)、位置 3 の値は \(A+C\)、位置 4 の値は \(A+B+C+D)\) である。\(D\) 内の合計は \(4+1-(2+3)\) として計算できる。
明らかに、2 つの矩形の合計の差は 8 つの参照で計算できる。上で定義した 2 つの矩形特徴には隣接する矩形の合計が含まれるため、6 つの配列参照で計算できる。3 つの矩形特徴の場合は 8 つ、4 つの矩形特徴の場合は 9 つである。
積分画像のもう 1 つの動機は、Simard らの「ボックスレット」研究に由来する[17]。著者らは、線形演算 (例: \(f・g\)) の場合、逆演算が結果に適用されれば、任意の可逆線形演算を \(f\) または \(g\) に適用できることを指摘している。たとえば畳み込みの場合、微分演算子が画像とカーネルの両方に適用されると、結果は二重積分される必要がある。 \[ f*g=\int\int(f'*g') \]
著者らはさらに、\(f\) と \(g\) の導関数が疎である場合 (または疎にできる場合)、畳み込みが大幅に高速化されることを示している。同様の洞察として、逆関数が \(g\) に適用される場合、可逆線形演算が \(f\) に適用できるという点が挙げられる。 \[ (f'')*\Bigg(\int\int g\Bigg)=f*g \]
この枠組みで見ると、矩形の合計の計算はドット積\(i・r\)として表現できる。ここで、\(i\)は画像、\(r\)はボックス・カー画像(関心のある矩形内では値1、外側では値0)である。この演算は次のように書き直すことができる。 \[ i・r=\Bigg(\int\int i\Bigg)・r'' \] 積分画像は、実際には画像の二重積分である (最初に行に沿って、次に列に沿って)。矩形の 2 次導関数 (最初に行に沿って、次に列に沿って) により、長方形の角に 4 つのデルタ関数が生成される。2 番目のドット積の評価は、4 回の配列アクセスで実行される。
矩形特徴は、ステアラブルフィルタ [5, 7] などの別の手段と比較すると、いくぶん原始的である。ステアラブルフィルタとその類似物は、境界の詳細な分析、画像圧縮、テクスチャ分析に適している。対照的に、矩形特徴は、エッジ、バー、その他の単純な画像構造の存在に敏感であるが、かなり粗い。ステアラブルフィルタとは異なり、使用できる方向は垂直と水平のみである。ただし、矩形特徴の集合は、効果的な学習をサポートする豊富な画像表現を提供するように見える。矩形特徴の極めて高い計算効率は、柔軟性の限界を十分に補う。
積分画像法の計算上の利点を理解するために、画像のピラミッドを計算するより一般的なアプローチを検討する。ほとんどのオブジェクト検出システムと同様に、検出器は入力をさまざまなスケールでスキャンする。24 x 24 ピクセルのサイズでオブジェクトが検出される基本スケールから始めて、画像はそれぞれ前の画像の 1.25 倍大きい11種類のスケールでスキャンされる。一般的なアプローチでは、それぞれが前の画像の 1.25 倍小さい11画像のピラミッドを計算する。次に、固定スケールの検出器がこれらの各画像をスキャンする。ピラミッドの計算は簡単であるが、かなりの時間がかかる。一般的なハードウェアに実装すると、15 フレーム/秒でピラミッドを計算することは非常に困難である4。
4 11レベルのピラミッドのピクセルの総数は、約 \(55*384*288=6082560\) である。各ピクセルの計算には 10 回の演算が必要であることを考えると、ピラミッドには約 60,000,000 回の演算が必要である。1 秒あたり15フレームの処理速度を達成するには、1 秒あたり約 900,000,000 回の演算が必要になる。
対照的に、我々は意味のある特徴セットを定義した。これは、1 つの特徴を、いくつかの操作で任意のスケールと場所で評価できるという特性を持っている。セクション 4 では、効果的な顔検出器が、わずか 2つの長方形の特徴で構築できることを示す。これらの特徴の計算効率を考えると、顔検出プロセスは、あらゆるスケールで 15 フレーム/秒で画像全体に対して完了できる。これは、11 レベルの画像ピラミッドのみを評価するのに必要な時間よりも短い時間である。このタイプのピラミッドを必要とする手順は、必然的に我々の検出器よりも遅くなる。
特徴セットとポジティブおよびネガティブ画像のトレーニングセットが与えられれば、分類関数を学習するために任意の数の機械学習アプローチを使用できる。Sung と Poggio はガウスモデルの組み合わせを使用している[18]。Rowley、Baluja、Kanade は、単純な画像特徴の小さなセットとニューラルネットワークを使用している [13]。Osuna らはサポートベクターマシンを使用した [9]。最近では、Roth らが新しい珍しい画像表現を提案し、Winnow 学習手順を使用した [12]。
各画像サブウィンドウには 45,396 個の長方形特徴が関連付けられていることを思い出してもらいたい。この数はピクセル数よりはるかに大きい。各特徴は非常に効率的に計算できるが、完全なセットを計算するには法外なコストがかかる。実験によって裏付けられた我々の仮説は、これらの特徴のごく一部を組み合わせることで効果的な分類器を形成できるというものである。主な課題は、これらの特徴を見つけることである。
我々のシステムでは、AdaBoost の変種が、特徴の選択と分類器のトレーニングの両方に使用されている [6]。元の形式では、AdaBoost 学習アルゴリズムは、単純な学習アルゴリズムの分類パフォーマンスを向上させるために使用される (たとえば、単純なパーセプトロンのパフォーマンスを向上させるために使用される場合がある)。これは、一連の弱い分類関数を組み合わせて、より強力な分類器を形成することによって行われる。ブースティングの用語では、単純な学習アルゴリズムは弱学習器と呼ばれる。したがって、たとえば、パーセプトロン学習アルゴリズムは、可能なパーセプトロンの集合を検索し、分類エラーが最も低いパーセプトロンを返す。学習器が弱いと呼ばれるのは、最良の分類関数でさえトレーニング データを適切に分類するとは期待されないためである (つまり、特定の問題では、最良のパーセプトロンでもトレーニング データを正しく分類できるのは 51% の場合のみである)。弱学習器をブーストするには、一連の学習問題を解く必要がある。最初の学習ラウンドの後、サンプルは、以前の弱分類器によって誤って分類されたものを強調するために、再度重み付けされる。最終的な強分類器は、しきい値に続く弱分類器の重み付けされた組み合わせであるパーセプトロンの形をとる。5
AdaBoost 学習手順によって提供される形式的な保証は非常に強力である。Freund と Schapire は、強力な分類器のトレーニング エラーがラウンド数に応じて指数関数的にゼロに近づくことを証明した。さらに重要なことは、汎化性能に関する多くの結果が後に証明されたことである [15]。重要な洞察は、汎化性能はサンプルのマージンに関連しており、AdaBoost は大きなマージンを迅速に達成するという点である。
従来の AdaBoost 手順は、貪欲な特徴選択プロセスとして簡単に解釈できる。重み付けされた多数決を使用して多数の分類関数を結合するブースティングの一般的な問題を考えてみよう。課題は、優れた分類関数に大きい重みを、劣った分類関数に小さい重みを関連付けることである。AdaBoost は、優れた分類関数の小さな集合を選択する積極的なメカニズムであるが、それでもかなりの多様性がある。弱分類器と特徴の類似点を描き出すと、AdaBoost は、優れた「特徴」を少数見つけ出す効果的な手順であるが、それでもかなりの多様性がある。
このアナロジーを完成させる実用的な方法の 1 つは、弱学習器を、それぞれが 1つの特徴に依存する分類関数のセットに制限することである。この目標をサポートするために、弱学習アルゴリズムは、正の例と負の例を最もよく分離する単一の矩形の特徴を選択するように設計されている (これは、画像データベース検索の領域における [2] のアプローチに似ている)。各特徴について、弱学習器は、誤分類される例の数を最小限に抑える最適なしきい値分類関数を決定する。したがって、弱分類器 (\(h_j(x)\)) は、特徴 (\(f_j\))、しきい値 (\(\theta_j\))、および不等号の方向を示すパリティ (\(p_j\)) で構成される。 \[ h_j(x)= \begin{cases} 1 & if p_jf_j(x)\lt p_j\theta_j\\ 0 & otherwise \end{cases} \] ここで、\(x\) は画像の 24x24 ピクセルのサブウィンドウである。
実際には、単一の特徴では、低いエラーで分類タスクを実行できない。プロセスの初期に選択された特徴は、0.1 ~ 0.3 のエラー率をもたらす。タスクがより困難になるにつれて、後のラウンドで選択された特徴は、0.4 ~ 0.5 のエラー率をもたらす。表 1 に学習アルゴリズムを示す。
表 1: クエリをオンラインで学習するためのブースティング アルゴリズム。\(T\) 個の仮説はそれぞれ単一の特徴を使用して構築される。最終的な仮説は、\(T\) 個の仮説の加重線形結合であり、重みはトレーニング エラーに反比例する。
一般的な特徴選択手順は数多く提案されている(レビューについては[20]の第8章を参照)。最終的なアプリケーションでは、大部分の特徴を破棄する非常に積極的なプロセスが必要だった。同様の認識問題に対して、Papageorgiouらは特徴分散に基づく特徴選択のスキームを提案した[10]。彼らは合計1734個の特徴から37個の特徴を選択するという良好な結果を実証した。これは大幅な削減ではあるが、画像サブウィンドウごとに評価される特徴の数はまだかなり多い。
Roth らは、Winnow 指数パーセプトロン学習規則 [12] に基づく特徴選択プロセスを提案している。著者らは、各ピクセルが \(d\) 次元のバイナリ ベクトルにマッピングされる非常に大規模で珍しい特徴セットを使用している(特定のピクセルが範囲 \([0,d-1]\) で値 \(x\) を取る場合、\(x\) 番目の次元は 1 に設定され、他の次元は 0 に設定される)。各ピクセルのバイナリ ベクトルは連結されて、\(nd\) 次元 (\(n\) はピクセル数) の単一のバイナリ ベクトルを形成する。分類規則はパーセプトロンであり、入力ベクトルの各次元に 1 つの重みを割り当てる。Winnow 学習プロセスは、これらの重みの多くが 0 になるソリューションに収束する。それでも、非常に多数の特徴が保持される (おそらく数百または数千)。
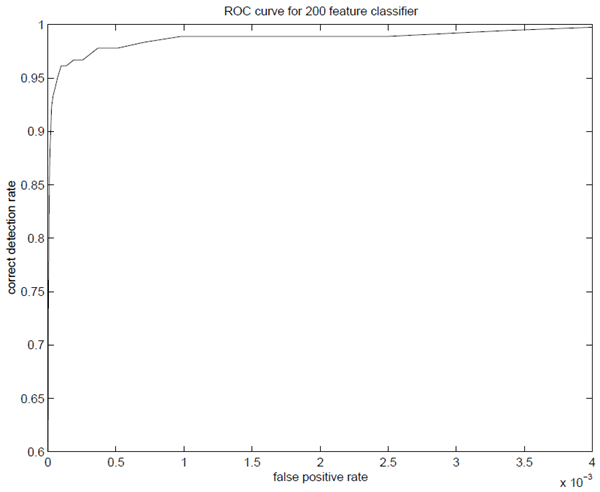
最終システムのトレーニングとパフォーマンスの詳細はセクション 5 で説明するが、いくつかの簡単な結果についても議論する価値がある。初期実験では、200 個の特徴から構築された分類器が妥当な結果を生み出すことが実証された (図 4 を参照)。検出率が 95% の場合、分類器はテスト データセットで 14084 分の 1 の誤検出率を生じた。
顔検出のタスクでは、AdaBoost によって選択された最初の矩形特徴は意味があり、簡単に解釈できる。選択された最初の特徴は、目の領域が鼻や頬の領域よりも暗いことが多いという特性に焦点を当てているようである (図 5 を参照)。この特徴は検出サブウィンドウと比較して比較的大きく、顔のサイズと位置にあまり影響されないはずである。選択された 2 番目の特徴は、目が鼻梁よりも暗いという特性に依存している。

図 5: AdaBoost によって選択された最初の特徴と 2 番目の特徴。2 つの特徴は上段に表示され、下段の典型的なトレーニング顔に重ねて表示される。最初の特徴は、目の領域と頬の上部の領域の間の強度の差を測定する。この特徴は、目の領域が頬よりも暗いことが多いという観察に基づいている。2 番目の特徴は、目の領域の強度を鼻梁の強度と比較する。
要約すると、200 個の特徴を持つ分類器は、矩形特徴から構築されたブースト分類器が物体検出に効果的な手法であるという最初の証拠を提供する。検出の点では、これらの結果は説得力があるが、多くの実際のタスクには十分ではない。計算の点では、この分類器はおそらく他の公開されたシステムよりも高速で、384 x 288 ピクセルの画像をスキャンするのに 0.7 秒しかかからない。残念ながら、検出パフォーマンスを向上させる最も単純な手法である分類器への特徴の追加は、計算時間を直接増加させる。
このセクションでは、計算時間を大幅に短縮しながら検出性能を向上させる分類器のカスケードを構築するアルゴリズムについて説明する。重要な洞察は、負のサブウィンドウの多くを棄却しながら、ほぼすべての正のインスタンスを検出する、より小さく、したがってより効率的なブースト分類器を構築できることである。より複雑な分類器が呼び出される前に、より単純な分類器を使用してサブウィンドウの大部分を棄却し、低い誤検出率を実現する。
カスケードの各段階は、AdaBoost を使用して分類器をトレーニングすることで構築される。2 つの特徴を持つ強力な分類器から始めて、強力な分類器のしきい値を調整して偽陰性を最小限に抑えることで、効果的な顔フィルターを取得できる。初期の AdaBoost しきい値 \(\frac{1}{2}\sum_{t=1}^T\alpha_t\) は、トレーニング データでエラー率が低くなるように設計されている。しきい値が低いほど、検出率と偽陽性率が高くなる。検証トレーニング セットを使用して測定されたパフォーマンスに基づいて、2 つの特徴を持つ分類器を調整して、偽陽性率 40% で顔を 100% 検出できる。この分類器で使用される 2 つの特徴の説明については、図 5 を参照。
2 つの特徴を持つ分類器の検出性能は、物体検出システムとして許容できるレベルには程遠いものである。しかし、分類器は、非常に少ない操作で、さらに処理を必要とするサブウィンドウの数を大幅に減らすことができる。
2 つの特徴を持つ分類器は、約 60 個のマイクロプロセッサ命令に相当する。これより単純なフィルタでより高い棄却率を達成できるとは考えにくいようである。比較すると、単純な画像テンプレートまたは単層パーセプトロンをスキャンするには、サブウィンドウごとに少なくとも 20 倍の操作が必要になる。
検出プロセスの全体的な形態は、縮退した決定木、いわゆる「カスケード」[11]である(図6参照)。最初の分類器から肯定的な結果が得られると、非常に高い検出率を実現するように調整された2番目の分類器の評価が開始される。2番目の分類器から肯定的な結果が得られると、3番目の分類器が評価を開始し、これが繰り返される。どの時点でも否定的な結果が得られると、そのサブウィンドウは即座に棄却される。
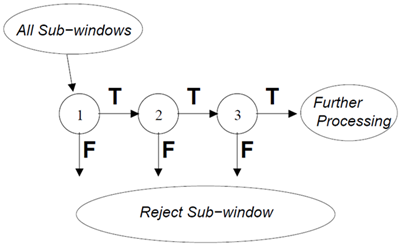
図6:検出カスケードの模式図。一連の分類器が各サブウィンドウに適用される。最初の分類器は、非常に少ない処理で多数の負例を棄却する。後続の層は、追加の負例を棄却するが、追加の計算を必要とする。数段階の処理を経て、サブウィンドウの数は大幅に減少する。その後の処理は、カスケードの追加段階(我々の検出システムのように)や、代替の検出システムなど、あらゆる形態で行うことができる。
カスケード構造は、単一の画像においてサブウィンドウの圧倒的多数がネガティブであるという事実を反映している。そのため、カスケードは可能な限り早い段階で、ネガティブなインスタンスをできるだけ多く棄却しようとする。ポジティブなインスタンスはカスケード内のすべての分類器の評価をトリガーするが、これは極めて稀なイベントである。
決定木と同様に、後続の分類器は、前の段階をすべて通過した例を用いて学習される。その結果、2番目の分類器は最初の分類器よりも難しいタスクに直面することになる。最初の段階を通過した例は、典型的な例よりも「難しい」。より深い分類器が直面するより難しい例は、受信器動作特性(ROC)曲線全体を下方に押し下げる。所定の検出率では、より深い分類器はそれに応じて偽陽性率が高くなる。
カスケード設計プロセスは、一連の検出目標と性能目標に基づいて決定される。顔検出タスクにおいて、過去のシステムは良好な検出率(85~95%)と極めて低い偽陽性率 (\(10^{-5}\)または\(10^{-6}\)程度)を達成している。カスケード段数と各段のサイズは、計算量を最小限に抑えながら同様の検出性能を達成するのに十分なものでなければならない。学習済みのカスケード分類器を与えられた場合、カスケードの偽陽性率は \[ F=\prod_{i=1}^Kf_i \] ここで、\(F\)はカスケード分類器の偽陽性率、\(K\)は分類器の数、\(f_i\)は\(i\)番目の分類器が通過したサンプルに対する偽陽性率である。検出率は \[ D=\prod_{i=1}^Kd_i \] ここで、\(D\) はカスケード分類器の検出率、\(K\) は分類器の数、\(d_i\) は \(i\) 番目の分類器が通過した例に対する検出率である。
全体的な偽陽性率と検出率の具体的な目標が与えられれば、カスケードプロセスの各段階における目標率を決定できる。例えば、10段階の分類器で各段階の検出率が0.99であれば、\(0.9\)という検出率を達成できる(\(0.9\approx 0.99^{10}\)であるため)。この検出率を達成するのは困難な作業のように思えるかもしれないが、各段階で偽陽性率が約30%(\(0.30^{10}\approx 6\times10^{-6}\))に抑えられれば十分であるため、はるかに容易になる。
実画像をスキャンする際に評価される特徴の数は、必然的に確率的なプロセスとなる。任意のサブウィンドウは、カスケードを1つずつ分類器を通して下方に進み、ウィンドウがネガティブと判断されるまで、あるいは稀に各テストに合格してポジティブとラベル付けされるまで続く。このプロセスの想定される動作は、典型的なテストセットにおける画像ウィンドウの分布によって決まる。各分類器の重要な指標は「陽性率」、つまり対象物体を含む可能性があるとラベル付けされたウィンドウの割合である。評価される特徴の想定される数は、以下の式で表される。 \[ N=n_0+\sum_{i=1}^K\Bigg(n_i\prod_{j\lt i}p_j\Bigg) \] ここで、\(N\)は評価される特徴量の期待値、\(K\)は分類器の数、\(p_i\)は\(i\)番目の分類器の陽性率、\(n_i\)は\(i\)番目の分類器に含まれる特徴量の数である。興味深いことに、物体は非常にまれであるため、「陽性率」は実質的に偽陽性率と等しくなる。
カスケードの各要素を学習するプロセスには、ある程度の注意が必要である。セクション3で紹介したAdaBoostの学習手順は、エラーを最小限に抑えることのみを目的としており、高い誤検知率を犠牲にして高い検出率を達成することを目的として設計されているわけではない。これらのエラーをトレードオフするシンプルで非常に一般的な方法の一つは、AdaBoostによって生成されるパーセプトロンのしきい値を調整することである。しきい値を高くすると、誤検知は少なくなり、検出率は低くなる。しきい値を低くすると、誤検知は多くなるが、検出率は高くなる。現時点では、このようにしきい値を調整することで、AdaBoostが提供する学習と汎化の保証が維持されるかどうかは明らかではない。
全体的な学習プロセスには、2種類のトレードオフが存在する。多くの場合、特徴量が多い分類器は、より高い検出率と低い誤検出率を実現する。同時に、特徴量が多い分類器は計算に多くの時間を必要とする。原理的には、次のような最適化フレームワークを定義することができる。
\(F\)と\(D\)の目標値が与えられた場合、特徴量の期待値\(N\)を最小化するために、トレードオフが行われる。残念ながら、この最適値を見つけることは非常に難しい問題である。
実際には、非常にシンプルなフレームワークを使用して、非常に効率的で効果的な分類器を生成する。ユーザーは、\(f_i\) と \(d_i\) の最小許容レートを選択する。カスケードの各層は AdaBoost によってトレーニングされ(表 1 を参照)、使用される特徴の数は、そのレベルのターゲット検出率と偽陽性率が満たされるまで増やす。レートは、現在の検出器を検証セットでテストすることで決定される。全体のターゲット偽陽性率がまだ満たされていない場合は、カスケードに別の層が追加される。後続の層をトレーニングするためのネガティブセットは、オブジェクトのインスタンスがまったく含まれていない画像セットで現在の検出器を実行して検出されたすべての偽検出を収集することで取得される。このアルゴリズムの詳細は、表 2 に示されている。
カスケードアプローチの実現可能性を調査するため、2つのシンプルな検出器を学習させた。1つは200特徴を持つモノリシックな分類器、もう1つは20特徴を持つ分類器10個のカスケードである。カスケードの第1段階の分類器は、5,000個の顔画像と、顔以外の画像からランダムに選択された10,000個の非顔サブウィンドウを用いて学習した。第2段階の分類器は、同じ5,000個の顔画像と、第1段階の分類器の誤検知5,000件を用いて学習した。このプロセスは継続され、後続の段階は前の段階の誤検知を用いて学習された。
200特徴を持つモノリシック分類器は、カスケード分類器の全段階の学習に使用されたすべてのサンプルの統合に基づいて学習された。カスケード分類器を参照しないと、モノリシック分類器を学習するための非顔画像学習サンプルセットを選択することが困難になる可能性があることに注意。もちろん、すべての非顔画像から可能なすべてのサブウィンドウを使用することもできるが、学習時間が非現実的に長くなる。カスケード分類器を順次学習する方法では、簡単なサンプルを除外し、「難しい」サンプルに焦点を当てることで、非顔画像学習セットを効果的に削減する。
カスケードに似た概念は、Rowleyら[13]が説明した顔検出システムにも見られる。Rowleyらは2つのニューラルネットワークを学習させた。1つは中程度の複雑さで、画像の小さな領域に焦点を当て、低い偽陽性率で顔を検出した。また、Rowleyらは、はるかに高速で、画像のより広い領域に焦点を当て、高い偽陽性率で顔を検出した2つ目のニューラルネットワークも学習させた。Rowleyらは、より高速な2つ目のネットワークを用いて画像を事前スクリーニングし、より低速でより正確なネットワークのための候補領域を探した。正確な値を特定することは困難であるが、Rowleyらの2つのネットワークを用いた顔検出システムは、既存の顔検出システムの中で最も高速であると考えられる。6 我々のシステムも同様のアプローチを採用しているが、この2段階カスケードを32段階に拡張している。
6 公開されている他の検出器では、パフォーマンスの詳細について議論することを怠っていたり、大規模で困難なトレーニング セットでの検出率や誤検出率を公開したことがなかったりする。
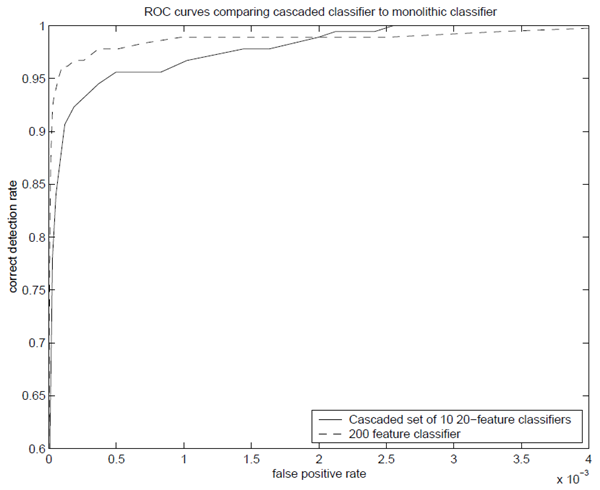
図7: 200特徴量分類器と、20特徴量分類器10個を含むカスケード型分類器を比較したROC曲線。精度に大きな差はないが、カスケード型分類器の速度はほぼ10倍高速である。
カスケード型検出プロセスの構造は、本質的には退化した決定木の構造であり、Amit と Geman [1] の研究と関連している。固定の検出器を使用する手法とは異なり、Amit と Geman は、単純な画像特徴の異常な共起を利用して、より複雑な検出プロセスの評価をトリガーするという別の観点を提案している。このようにして、潜在的な画像の位置やスケールの多くで検出プロセス全体を評価する必要はない。この基本的な洞察は非常に貴重であるが、実装においては、まずあらゆる位置で何らかの特徴検出器を評価する必要がある。次に、これらの特徴はグループ化され、異常な共起が検索される。実際には、検出器の形状とそれが使用する特徴は非常に効率的であるため、あらゆるスケールと位置で検出器を評価する償却コストは、画像全体でエッジを見つけてグループ化するよりもはるかに高速である。
Fleuret と Geman は最近、一連のテストによって特定のスケールと場所に顔が存在することを示す顔検出手法を発表した [4]。Fleuret と Geman が測定した画像特性は細かいエッジの分離であり、単純であらゆるスケールに存在し、ある程度解釈可能な矩形特徴とはまったく異なる。この 2 つのアプローチは学習哲学も根本的に異なる。Fleuret と Geman の学習プロセスの目的は密度推定と密度識別であるが、我々の検出器は純粋に識別的である。最後に、Fleuret と Geman のアプローチの偽陽性率は、Rowley らやこのアプローチなどの以前のアプローチよりも高いようである。残念ながら、この論文ではこの種の定量的な結果は報告されていない。含まれているサンプル画像には、それぞれ 2~10 個の偽陽性がある。
このセクションでは、最終的な顔検出システムについて説明する。カスケード型検出器の構造と学習の詳細、そして大規模な実世界テストセットでの結果についても説明する。
顔のトレーニング セットは、24 x 24 ピクセルの基本解像度に拡大縮小され位置合わせされた、手動でラベル付けされた 4916 個の顔から構成されている。顔は、ワールド ワイド ウェブのランダム クロール中にダウンロードされた画像から抽出された。いくつかの典型的な顔の例を図 8 に示す。これらの例には、Rowley ら [13] や Sung [18] が使用した例よりも頭部が多く含まれていることに注目してもらいたい。最初の実験では、顔がよりタイトに切り取られた 16 x 16 ピクセルのトレーニング画像も使用したが、結果は若干悪くなった。おそらく、24 x 24 の例には、顎と頬の輪郭や髪の生え際など、精度の向上に役立つ追加の視覚情報が含まれている。使用される特徴の性質上、サブウィンドウのサイズが大きくてもパフォーマンスは低下しない。実際、大きなサブウィンドウに含まれる追加情報は、検出カスケードの早い段階で顔以外を除外するために使用できる。

最終的な検出器は、合計 4297 個の特徴を含む 32 層の分類器のカスケードである。
カスケードの最初の分類器は、2 つの特徴を使用して構築され、顔以外の約 60% を棄却するが、顔をほぼ 100% 正しく検出する。次の分類器は 5 つの特徴を持ち、顔以外の 80% を棄却するが、顔をほぼ 100% 検出する。次の 3 つの層は、20 の特徴の分類器、その次に 2 つの 50特徴の分類器、その次に 5 つの 100 特徴の分類器、そして 20 の 200特徴の分類器である。層ごとの特徴の数は、試行錯誤のプロセスを通じて選択され、偽陽性率が大幅に低下するまで特徴の数が増加された。検証セットの偽陽性率がほぼゼロになりながらも、高い正答率を維持するまで、さらにレベルが追加された。最終的な層の数と各層のサイズは、最終的なシステム パフォーマンスには重要ではない。
2、5、および最初の20個の特徴を持つ分類器は、表1に示すAdaboost学習手順を用いて、4,916個の顔と10,000個の顔以外のサブウィンドウ(サイズも24×24ピクセル)を用いて学習された。顔以外のサブウィンドウは、顔を含まない9,500枚の画像セットからランダムにサブウィンドウを選択することで収集された。分類器ごとに異なる顔以外のサブウィンドウセットを使用することで、分類器がある程度独立し、同じ特徴を使用しないようにした。
後続レイヤーの学習に用いられる非顔画像は、部分カスケードを大規模な非顔画像にスキャンし、偽陽性を収集することで取得された。各レイヤーでは、最大6000個の非顔サブウィンドウが収集された。9500枚の非顔画像には、約3億5000万個の非顔サブウィンドウが含まれている。
32層検出器全体の学習時間は、466MHzのAlphaStation XP900 1台で数週間程度だった。この骨の折れる学習プロセスの中で、学習アルゴリズムにいくつかの改良点が見つかった。これらの改良点については別途説明するが、これにより学習時間が100分の1に短縮された。
カスケード検出器の速度は、スキャンされたサブウィンドウごとに評価される特徴の数に直接関係している。セクション4.1で説明したように、評価される特徴の数はスキャンされる画像によって異なる。MIT + CMUテストセット[13]で評価すると、合計4297個の特徴のうち平均8個の特徴がサブウィンドウごとに評価される。これは、サブウィンドウの大部分がカスケードの最初のレイヤーまたは2番目のレイヤーによって棄却されるため可能になる。700 Mhz Pentium IIIプロセッサでは、顔検出器は384 x 288ピクセルの画像を約0.067秒で処理できる(後述するように、開始スケール1.25およびステップサイズ1.5を使用)。これは、Rowley-Baluja-Kanade検出器[13]よりも約15倍高速であり、Schneiderman-Kanade検出器[16]よりも約600倍高速である。
トレーニングに使用したすべてのサンプルサブウィンドウは、異なる照明条件の影響を最小限に抑えるために分散が正規化されている。したがって、検出時にも正規化が必要である。画像サブウィンドウの分散は、一対の積分画像を使用して簡単に計算できる。\(\sigma^2=m^2-\frac{1}{N}\sum c^2\) を思い出してもらいたい。ここで、\(\sigma\) は標準偏差、\(m\) は平均、\(x\) はサブウィンドウ内のピクセル値である。サブウィンドウの平均は積分画像を使用して計算できる。二乗ピクセルの合計は、画像の二乗の積分画像を使用して計算される(つまり、スキャン処理で 2 つの積分画像が使用される)。スキャン中、画像正規化の効果は、ピクセルを操作するのではなく、特徴値を後で乗算することで実現できる。
最終的な検出器は、画像全体にわたって複数のスケールと位置でスキャンされる。スケーリングは、画像ではなく検出器自体をスケーリングすることで実現される。このプロセスは、特徴を任意のスケールで同じコストで評価できるため、理にかなっている。1.25倍離れたスケールのセットを使用することで、良好な結果が得られた。
検出器も位置にわたってスキャンされる。後続の位置は、ウィンドウをピクセル数 \(\Delta\) シフトすることによって取得される。このシフト処理は検出器のスケールによって影響を受ける。現在のスケールが \(s\) の場合、ウィンドウは \([s\Delta]\) シフトされる。ここで、 \([ ]\) は丸め演算である。 \(\Delta\) の選択は、検出器の速度と精度の両方に影響する。トレーニング画像にはある程度の並進変動があるため、学習した検出器は、画像内の小さなシフトにもかかわらず、優れた検出性能を実現する。その結果、検出器のサブウィンドウは一度に 1 ピクセル以上シフトできる。ただし、1 ピクセル以上のステップ サイズでは、検出率がわずかに低下する傾向があるが、偽陽性の数も減少する。2 つの異なるステップ サイズの結果を示す。
最終的な検出器は、移動やスケールの小さな変化に敏感ではないないため、スキャン画像内の各顔の周囲では通常、複数の検出が行われる。これは、ある種の誤検知にも当てはまる。実際には、顔ごとに1つの最終検出を返す方が理にかなっている場合が多くある。この目的のために、検出されたサブウィンドウを後処理し、重複する検出を1つの検出に結合することが有用である。
これらの実験では、検出結果は非常に単純な方法で結合される。まず、検出結果の集合は互いに素なサブセットに分割される。2つの検出結果の境界領域が重なる場合、それらは同じサブセットに属す。各分割から1つの最終的な検出結果が生成される。最終的な境界領域の角は、集合内のすべての検出結果の角の平均となる。
場合によっては、この後処理により、重複する偽陽性のサブセットが単一の検出に削減されるため、偽陽性の数が減少する。
我々はMIT+CMU正面顔テストセット[13]でシステムをテストした。このセットは507のラベル付き正面顔を含む130枚の画像から構成される。このテストセットにおける検出器の性能を示すROC曲線を図9に示す。ROC曲線を作成するために、最終層の分類器におけるパーセプトロンの閾値を \(+\infty\) から \(-\infty\) に調整する。閾値を \(+\infty\) に調整すると、検出率0.0、偽陽性率0.0となる。しかし、閾値を \(-\infty\) に調整すると、検出率と偽陽性率の両方が増加するが、ある一定の点までしか増加しない。どちらの率も、検出カスケードから最終層を除いた率よりも高くすることはできない。実質的に、閾値 \(-\infty\) はその層を削除することと同等である。検出率と偽陽性率をさらに増加させるには、カスケード内の次の分類器の閾値を下げる必要がある。したがって、完全なROC曲線を構築するために、分類器層は削除される。他のシステムとの比較を容易にするため、ROC曲線のX軸には偽陽性率ではなく偽陽性数を使用します。偽陽性率を計算するには、スキャンされたサブウィンドウの総数で割るだけです。\(\Delta=1.0\)で開始スケールが1.0の場合、スキャンされたサブウィンドウの数は75,081,800です。\(\Delta=1.5\)で開始スケールが1.25の場合、スキャンされたサブウィンドウの数は18,901,947である。
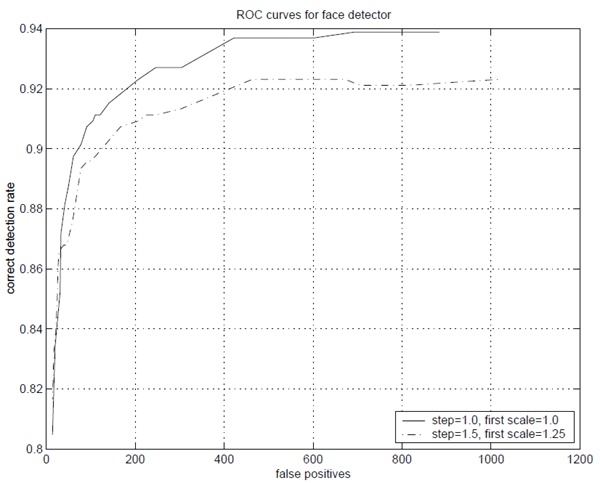
図9: MIT+CMUテストセットにおける顔検出器のROC曲線。検出器は、ステップサイズ1.0、開始スケール1.0(スキャンされたサブウィンドウ数75,081,800)で1回実行され、その後、ステップサイズ1.5、開始スケール1.25(スキャンされたサブウィンドウ数18,901,947)で再度実行された。どちらの場合も、スケール係数は1.25が使われた。
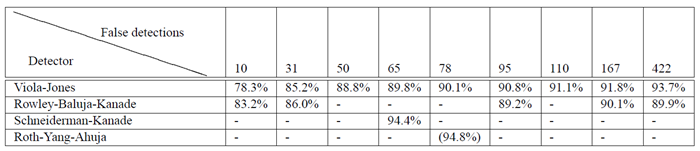
表 3: 130 枚の画像と 507 個の顔を含む MIT + CMU テスト セットにおけるさまざまな数の誤検出の検出率。
SungとPoggioの顔検出器[18]は、MIT+CMUテストセットのMITサブセットでテストされた。これは、CMU部分がまだ存在していなかったためである。MITテストセットには23枚の画像と149個の顔が含まれている。それらは5つの誤検出で79.9%の検出率を達成した。我々のMITテストセットでの検出率は、5つの誤検出で77.8%である。
図 10 は、MIT + CMU テスト セットのいくつかのテスト画像に対する顔検出器の出力を示している。

図 10: MIT + CMU テスト セットからのいくつかのテスト画像に対する顔検出器の出力。
我々は、計算時間を最小限に抑えながら高い検出精度を実現する物体検出手法を提示した。この手法を用いて、従来の手法よりも約15倍高速な顔検出システムを構築した。別途説明する予備実験では、歩行者などの他の物体に対しても、この手法で非常に効率的な検出器を構築できることが示されている。
この論文では、非常に汎用的で、コンピューター ビジョンや画像処理に幅広く応用できる可能性のある新しいアルゴリズム、表現、洞察をまとめている。
最初の貢献は、積分画像を用いて豊富な画像特徴量を計算する新しい手法である。真のスケール不変性を実現するために、ほぼすべての物体検出システムは複数の画像スケールで動作する必要がある。積分画像は、マルチスケール画像ピラミッドを計算する必要性を排除することで、物体検出に必要な初期画像処理を大幅に削減する。顔検出の分野では、その利点は極めて劇的である。積分画像を用いることで、画像ピラミッドを計算する前に顔検出が完了する。
積分画像は、Harr型特徴量を用いた他のシステム(Papageorgiouら [10] など)にもすぐに応用できるはずであるが、Harr型特徴量が有用となる可能性のあるあらゆるタスクに影響を与えることが予測される。初期実験では、同様の特徴セットが、顔の表情、頭の位置、物体の姿勢などを決定するパラメータ推定タスクにも有効であることが示されている。
本論文の2つ目の貢献は、AdaBoostに基づく特徴選択手法である。積極的かつ効果的な特徴選択手法は、様々な学習タスクに影響を与えるであろう。効果的な特徴選択ツールがあれば、システム設計者は非常に大規模かつ複雑な特徴セットを学習プロセスの入力として自由に定義できる。それでもなお、結果として得られる分類器は計算効率が高く、実行時に評価する必要がある特徴の数は少なくなる。また、結果として得られる分類器は非常に単純なものになる場合が多く、複雑な特徴の大規模なセットの中に、分類問題の構造を簡潔に捉える重要な特徴がいくつか見つかる可能性が高くなる。
本論文の3つ目の貢献は、計算時間を大幅に短縮しながら検出精度を向上させる分類器のカスケード構築手法である。カスケードの初期段階では、後続の処理を有望な領域に集中させるために、画像の大部分を除外する設計となっている。重要な点の1つは、提示されたカスケードが非常に単純で均質な構造になっていることである。Ittiらなどの従来の注意深いフィルタリング手法では、より複雑で異質なフィルタリング機構が提案されている[8]。同様に、AmitとGemanは、各段階の構造と処理が大きく異なる階層構造の検出を提案している[1]。均質なシステムは、実装と理解が容易なだけでなく、処理時間と検出性能の間でシンプルなトレードオフを実現できるという利点もある。
最後に、本論文では、広く研究されている難解な顔検出データセットを用いた一連の詳細な実験結果を示す。このデータセットには、照明スケール、ポーズ、カメラの変動など、非常に幅広い条件下での顔が含まれている。このように大規模で複雑なデータセットを用いた実験は困難で、時間もかかる。しかしながら、このような条件下で動作するシステムは、脆弱であったり、単一の条件セットに限定されたりすることはないと考えられる。さらに重要なのは、このデータセットから得られる結論が実験結果のアーティファクトである可能性は低いということである。
著者一同は、T. M. Murali氏、Jim Rehg氏、Tat-jen Cham氏、Rahul Sukthankar氏、Vladimir Pavlovic氏、そしてThomas Leung氏から有益なコメントをいただいたことに感謝いたします。Henry Rowley氏には、我々の顔検出器との比較のために、彼の顔検出器の実装を提供してくださったことに深く感謝いたします。